Jak wiadomo nie korzystam z programu Power Point. Jestem zdecydowanym zwolennikiem systemu LaTeX i beamera. Proste prezentacje przygotowuję korzystając z języka znaczników Markdown i programu pandoc do konwersji do PDF.
Obie były prowadzone z użyciem systemu Zoom. Zapewne nie wszyscy uczestnicy byli zaznajomieni z tym systemem. Ze zdziwieniem zauważyłem, że zwłaszcza trudno jest im udostępnić ekran prezentacji i bardzo często udostępniali ekran „edytora”.
W tradycyjnym układzie podłącza się rzutnik do komputera (laptopa) i dysponujemy dwoma „ekranami”: tym na komputerze i tym rzucanym przez rzutnik.
System operacyjny na ogół pozwala wybrać tryb pracy:
ta sama zawartość na obu ekranachalbo
dwa monitory.
W drugim przypadku Power Point pozwala na wyświetlenie prezentacji na rzutniku i wyświetlanie notatek na ekranie monitora. Gdy nie ma notatek, możemy zobaczyć aktualny slajd i slajd następny.
Rzecz cała gmatwa się dla podczas korzystania z Zooma w przypadku gdy nie ma rzutnika albo gdy mamy dwa monitory podłączone do komputera.
W pewnym sensie najprostszym rozwiązaniem może być eksport prezentacji do formatu PDF i wyświetlanie (i udostępnianie) okna przeglądarki PDF. Niestety w tym przypadku mogą zniknąć pewne możliwości oferowane rzez PowerPoint.
Zoom Help Center udostępnia artykuł na ten temat: Screen sharing a PowerPoint presentation. Najlepiej przetestować to w praktyce, ja postaram się pokrótce proponowane rozwiązania omówić (nie jestem w stanie — wobec braku komputera z Windowsem i PowerPointa — dokładniej tego opisać.)
Strona rozpatruje trzy sytuacje:
dwa monitory, na jednym pokaz slajdów, na drugim widok dla prelegenta
pojedynczy monitor i pokaz slajdów w okienku
pojedynczy monitor i pokaz prezentacji na pełnym ekranie.
Pokrótce omówię (za helpem) te trzy sytuacje. Zalecam jedna (gdy pojawiają się kłopoty) zaaranżować szybkie spotkanie z kolegą/koleżanką i przetestować typowe ustawienie.
Dwa monitory, na jednym pokaz slajdów, na drugim widok dla prelegenta
Otwórz w PowerPoint prezentację, którą zamierzasz prezentować.
Rozpocznij albo przyłącz się do spotkania Zoom
Naciśnij zielony guzik
Wybierz podstawowy monitor i kliknij Share Screen
Podczas udostępniania ekranu, przełącz PowePoint do trybu prezentacji klikając w jedną z ikonek na zakładce Prezentacja.
Widok prelegenta dostępny będzie na drugim monitorze.
Jeżeli udostępniłeś niewłaściwy monitor w PowerPoincie przełącz monitory (zrzut ekranu z angielskiej wersji PP)
Pojedynczy monitor z prezentacją w okienku
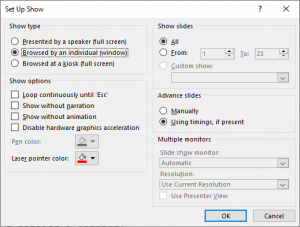
Po pierwsze trzeba przestawić program PowerPoint w tryb, w którym będzie pokazywał prezentację w oknie (a nie w trybie pełnoekranowym). Udostępnianie okna może być w pewnych sytuacjach prostsze: nie mamy dwu monitorów, a chcemy korzystać, na przykład, z przygotowanych informacji dla prelegenta.
Otwórz plik z prezentacją.
Na pasku Slide Show kliknij Ustawienia prezentacji:
Tam wybierz Prezentacja w indywidualnym oknie
Przełącz się w tryb prezentacji (wybierając Od początku albo Od bieżącego slajdu)
W Zoom rozpocznij albo przyłącz się do spotkania (akcja nie jest potrzebna gdy już jesteć uczestnikiem spotkania)
Udostępnij okno z prezentacją PowerPoint
Pojedynczy monitor z prezentacją w trybie pełnoekranowym
Otwórz plik z prezentacją
Przyłącz się do spotkania Zoom
Kliknij Udostępnianie ekranu
Wybierz monitor i udostępnij go
Udostępniając ekran przełącz się do PowerPoint1
Rozpocznij prezentację albo od bieżącego slajdu, albo od początku.
Dzisiejsze, poranne przeglądanie Internetu doprowadziło do ciekawego znaleziska. Rozpocząłem od komiksowej strony xkcd.
Później zajrzałem do wiki wyjaśniającej Co Autor chciał powiedzieć? Choć to akurat wydawało się dosyć oczywiste — podczas analizy danych całkiem często mamy do czynienia nie tyle z cyfrowym zestawem danych, ile z ich zobrazowaniem w postaci wykresu.
A tam znalazłem odniesienie do aplikacji pozwaljącej czytsć dane z wykresu: WebPlotDigitizer.
Po obejrzeniu tutoriali uważam, że obok aplikacji tabula (pozwalającej wyciągać dane z tabel PDF) jest warta zapamiętania.
Bardzo często, po dodaniu ilustracji, plik PDF puchnie do ogromnych rozmiarów. Przygotowując publikację do druku staramy się aby jakość ilustracji była jak najlepsza i czasami przesadzamy z tym.
Osobną sprawą jest przygotowanie ilustracji w takiej rozdzielczości, aby drukarz (albo redakcja nie narzekali). Nie będziemy zajmować się tym teraz.
Program Adobe Acrobat (w wersji pro) pozwala zapisać plik w wersji „zoptymalizowanej”. Opis tej funkcjonalności można znaleźć na stronach Adobe.
Co jednak zrobić gdy nie mamy dostępu do tego (płatnego) programu?
Program ghostscript oferuje zbliżoną funkcjonalność.
Podstawowe polecenie do optymalizacji wygląda tak:
Kluczowa opcja to -dPDFSETTINGS=/printer która stara się działać podobnie jak odpowiednie ustawienie w Adobe Acrobat. Inne wartości jakie może ona przyjmować to:
/prepress — najwyższa jakość, 300 dpi,
/printer — wysoka jakość, optymalizowane do wydruku, 300 dpi,
/ebook — niska jakość, 150 dpi,
/screen — do czytania na ekranie, ilustracje są skalowane do 72 dpi (co nie zawsze daje dobre efekty)
/default — ustawienia domyślne.
Wykonany test pozwolił skompresować plik o wielkości 5 M do:
244 K /screen
276 K /ebook
632 K /prepress
704 K /print
788 K /default
W przypadku plików PDF tworzonych przez narzędzia TeXowe warto skorzystać z programu pdfimages znajdującego się w linuksowym pakiecie poppler-utils. W przypadku Windows (nie testowałem) program znajduje się w paczce pakietu XpdfReader. Program nie tylko pozwala na wyodrębnienie ilustracji zawartych w pliku PDF (nie każdą ilustrację i nie z każdego pliku da się w ten sposób wyodrębnić) ale, w szczególności, program pozwala odpytać o wszystkie ilustracje znajdujące się w pliku PDF:
Shell
1
pdfimages-list plik.pdf
Dowiemy się w jakiej rozdzielczości są ilustracje. Po kompresji okaże się co z nimi zrobił ghostscript.
W opisywanym wcześniej przykładzie było sporo plików graficznych w rozdzielczości 945 dpi. Po kompresji zostały one odpowiednio zmniejszone (do 300 dpi) w przypadku /printer.
Wadą tak zrealizowanej kompresji jest to, że wszystkie „klikalne odsyłacze” w pliku PDF przestają być klikalne. I nie tyle jest to wina LaTeXa/ghostscripta ile raczej sposobu traktowania różnych obiektów podczas kompresji. Aby odnośniki pozostały klikalne — należy (nad)użyć opcji pdfa pakietu hyperref:
Najdziwniejszy jest zawód urzędnika administracyjnego Instytutu matematycznego:nie wie, czym administruje!
Hugo Steinhaus
W pewnym sensie jestem ogromnym zwolennikiem bibliometrii, choć z drugiej strony, mogę powiedzieć, że używana jest w zły sposób, który w znacznej części niweczy jej zalety. Nie można bowiem narzędzia podającego informacje strategiczne stosować do bieżącej taktyki.
Ale urzędnicy, którzy nie rozumieją tego czym administrują, potrzebują łatwych (i w miarę „automatycznych”) narzędzi oceny naukowców i ich grup. Bibliometria pasuje jak znalazł. A jak już naukowcy wiedzą, za pomocą jakich narzędzi są oceniani — rozpoczynają optymalizację. Gdy głównym kryterium jest:
liczba publikacji — publikują ogromne ilości przyczynkarskich prac wszędzie tam, gdzie chcą przyjąć;
liczba cytowań — tworzą „spółdzielnie” ułatwiające publikowanie, przynależność do nich jest opłacona koniecznością cytowania innych członków spółdzielni;
indeks H wydaje się być niezłą miarą starającą się ocenić i liczbę publikacji i liczbę ich cytowań (indeks równy N oznacza, że uczony ma N publikacji cytowanych więcej niż N razy). Ale ma też bardzo wiele wad, które próbowano zniwelować wymyślając różne jego modyfikacje.
Hirsch, poważny fizyk (podlegający również różnym automatycznym ocenom), dla żartu wymyślił ten (indeks H) wskaźnik i „wyliczył” go dla kilku znanych uczonych (noblistów i członków innych szanownych gremiów). I się przyjęło.
Co gorsza(?) naukowcy dosyć szybko przywiązali się do różnych miar ich dorobku i bardzo negatywnie reagują, gdy okazuje się, że jakiś wskaźnik zamiast im rosnąć — maleje.
Z drugiej strony wszyscy zdajemy sobie sprawę, że jeżeli ten sam parametr mierzymy za pomocą różnych przyrządów pomiarowych możemy dostać różne wyniki. Czasami różnice są niewielkie, czasami są znaczące, ale w każdym przypadku nabieramy wątpliwości do jakości urządzeń pomiarowych. Czasami jednak wynik (pomiaru) powstaje w efekcie złożonej procedury pomiarowej i obliczeniowej. W takiej sytuacji cała metodologia, zestaw dostępnych danych, założenia — wszystko ma wpływ na wyniki. Jeżeli dostaje się wyniki powtarzalne — trudno metodę kwestionować.
Politechnika Wrocławska jest uczelnią, która jako pierwsza w Polsce rozpoczęła zbieranie informacji na temat publikacji swoich pracowników. Są one gromadzone w bazie DONA. Oprócz tego podjęła poważny wysiłek aby informacje te przetwarzać dostarczając analizy zainteresowanym pracownikom i kierownictwu Politechniki Wrocławskiej. Uważam, że pracownicy tym zajmujący wykonują kawał bardzo dobrej i potrzebnej pracy.
Science Citation Index (SCI) powstał w latach 60. zeszłęgo stulecia i stał się podstawą „sławy” ISI (Institute for Scientific Information w Filadelfii). Charakterystyczne tomy SCI były podstawową pozycją w każdej „czytelni czasopism bieżących” i bardzo ważnym narzędziem pozwalającym (w czasach przed-internetowych) stosunkowo łatwo śledzić „sznureczek” cytowań jakiejś publikacji w czasie. SCI był wówczas, (zwłaszcza gdy egzemplarze publikacji zdobywało się wysyłając na adres autora pocztówkę–prośbę o odbitki) niezastąpionym narzędziem. Losy ISI były bardzo burzliwe, zmieniał on swoich właścicieli ale podstawowy serwis Web of Science ma się bardzo dobrze. Na przykład Fińska Akademia Nauk przedstawia systematyczne (co dwa lata) oceny nauki fińskiej przygotowywane na podstawie danych WoS (wykorzystując bibliometrię do ocen strategicznych).
Tomy SCI w czytelni
Nieco poźniejsza inicjatywa to różne próby wydawnictwa Elsevier do stworzenia wyszukiwarki prac naukowych (jak, na przykład Scirus), które przekształciły się w końcu w bazę Scopus. Podstawowa różnica, która wyróżnia serwis Scopus (i wszystkie z nim związane) to fakt, że Elsevier jest jednym z największych wydawców literatury naukowej i ma dostęp do wszystkich swoich publikacji. Jako jeden z pierwszych firma zadbała o stworzenie unikatowych identyfikatorów uczonych i podjęła działania, żeby łączyć ich z miejscem pracy.
Mendeley — (działa od 2007 roku) aplikacja i serwis społecznościowy będące (od 2013 roku) własnością firmy Elsevier.
Google Scholar (udostępniony w 2004 roku). Początkowo tylko wyszukiwarka, dziś również platforma informacyjna. Bardzo agresywnie przeszukuje udostępnione w Internecie pliki i łączy je z informacjami na stronach wydawnictw. Dzięki temu często udostępnia pełne teksty korzystając ze źródeł innych niż wydawców. Platforma informacyjna pozwala naukowcowi umieścić informacje o swoich pracach, a wyszukiwarka Google będzie „zliczała” automatycznie cytowania.
Microsofy Academic (powstał jako Microsoft Academic Research w roku 2006 jako odpowiedź na powstanie Google Scholar). Dosyć kiepsko radzi sobie na rynku, był zamykany, otwierany i w końcu został reaktywowany jako Microsoft Academic i zintegrowany z z wyszukiwarką Bing. Posiada sporą bazę danych publikacji naukowych (jedynie tam znalazłem jakąś wzmiankę o wniosku patentowym, którego kiedyś byłem współautorem; patent nie został przyznany).
Zotero — (działą od 2006 roku) aplikacja ułatwiająca gromadzenie metadanych i baz bibliograficznych. O ile pamiętam były jakieś plany udostępniania swoich baz bibliograficznych, ale nie do końca wiem jak to się skończyło.
Research Gate — (działa od 2008 roku) medium społecznościowe dla naukowców. Udostępnia podstawowe informacje o publikacjach oraz, bardzo czesto, ich pełne teksty. Przy czym dostępność pełnych tekstów czasami jest ograniczona wyłącznie dla innych użytkowników serwisu.
Academia.edu — (działa od 2008) komercyjne medium społecznościowe dla naukowców.
…
Wszystkie te firmy starają się stworzyć jakąś platformę wymiany informacji na temat publikacji. Modele biznesowe są różne, ale podstawą działania tych przedsięwzięć są gromadzone metadane i narzędzia do ich analizy. Jedną z podstawowych analiz jest zliczanie cytowań. Przyjrzyjmy się efektom pracy różnych serwisów. Do porównań wybrałem swoją współautorską pracę Optimum experimental design for a regression on a hypercube—generalization of Hoel’s result. Poniżej przedstawiam informacje o liczbie cytowań zaliczonych, przez różne serwisy:
Scopus (17)
WOS (17)
Microsoft Academic (19)
Google Scholar (23)
Dona (udostępnia publicznie jedynie cytowania po 2014 i tych jest tylko 2 (słownie dwa))
Nie jest tak, że wyniki różnią się drastycznie. Można powiedzieć, że praca została zacytowana 20 ± 3 razy. Nie wiemy, które z tych wyliczeń odrzucają autocytowania, nie wiemy (choć akurat tego to można czasami się dowiedzieć przy odrobinie chęci) czy 17 cytowań WOS to te same 17 cytowań ze skopusa.
Jak nie mamy pewności do liczby cytowań, to również indeks H (bożek wszystkich naukowców) będzie zaburzony: Według Google Scolara mój współczynnik za ostatnie pięć lat to 2 (a globalnie to 5). Według skopusa — jest on znacznie, znacznie niższy 🙁
Nie należy obrażać się na gorsze wyniki jakiegoś pomiaru, tylko cały czas pamiętać, że skoro oceniam kogoś za pomocą miarki skopusa to nie powinienem porównywać go z osobą ocenianą miarką Google Scholar. Wydaje się, że jest to elementarne założenie. Co niekoniecznie jest prawdą w różnego rodzaju wnioskach (na przykład o awans). Ale to już osobna historia.
Podsumowując zdaję sobie sprawę, że zestawienie, które przedstawiłem może być odbierane prze kogoś jako niesprawiedliwe. Ale proszę pamiętać, że skorzystałem z jednego narzędzia do oceny wszystkich. I wyniki są mniej-więcej porównywalne. Pierwsza część (podająca podstawowe informacja na temat naszych osiągnięć dotyczy okresu 2013–2018 (co jest napisane już w drugim ustępie), to jest nieco więcej niż pięć lat, ale zdajemy sobie sprawę, że rok 2018 ciągle jeszcze trwa). Cześć druga, dokonująca porównań z Wydziałem obejmuje okres dłuższy: 2010–2018 (co nie jest napisane, ale wynika z opisu osi wykresów).
Na stronach serwisu SciVal (dostęp może mieć, po zarejestrowaniu, każdy z sieci Politechniki Wrocławskiej) można się zapoznać z dostępna dokumentacją opisującą metodologię i znaczenie poszczególnych wskaźników. (Nie upubliczniam ich tutaj, bo nie mam pewności czy mogę to zrobić.)
Najnowsza wersja programu pandoc (do pobrania ze stron projektu) ma możliwość konwersji markdown do formatu pptx.
Teoretycznie (nie udało mi się tego jeszcze sprawdzić) można użyć dowolnego szablonu (w formacie .pptx lub .potx) podczas konwersji.
Poniżej efekty konwersji prostego pliku o zawartości
Kod źródłowy w markdown
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
---
author:
- 'A. U. Thor'
title: Prosta prezentacja
---
### Przykładowy slajd
Litwo! Ojczyzno moja! Ty jesteś jak zdrowie. Nazywał się żenił i dobył książeczkę z opieki panicz przed nim szedł kwestarz, Sędzia nagłym zwrotem głową rzekł - wprawdzie pękła jedna ściana okna bez wątpienia kusy piękny i knieje więc szanują przyjaciół jak kochał pana zwykł sam ku drzwiom odprowadzał i każdy.(Tekst wygenerowany automatycznie przez http://lipsum.pl/index.php)



 na zakładce Prezentacja.
na zakładce Prezentacja.