Jakieś trzy latat temu, po kolejnym alercie bezpieczeństwa dotyczącym edytora równań (Equation editor 3.0) firma Microsoft wypuściła poprawkę bezpieczeństwa usuwającą go ze wszystkich praktycznie swoich produktów.
Problem mnie nie dotyczył (ani nie dotyczy), a dowiedziałem się o nim dopiero kilka dni temu.
Pytanie jest takie: jakie to wygenerowało problemy:
Użytkownicy stracili możliwość edycji swoich starych dokumentów.
Użytkownicy (w wielu przypadkach) stracili możliwość „wyświetlania” przygotowanych wcześniej dokumentów, gdyż, wraz z usunięciem edytora równań, usunięto plik fontu potrzeby do prezentacji niektórych, występujących w równaniach znaków.
Co Microsoft zaproponował swoim użytkownikom:
zakup komercyjnego narzędzia MathType (97$ lub 57$ w wersji akademickiej)
lub upgrade do najnowszej wersji Worda, która (w większości przpadkow według firmy) będzie potrafiła skonwertować stare wzory do nowego formatu.
Historycznie na sprawę patrząc Microsoft na potrzeby MS Office kupił od firmy MathType edytor równań, ktory został zintegrowany z Officem. (podobnie zakupiony został PowerPoint).
Jaki stąd wniosek?
Podstawowy to chyba tylko jeden: Naukowcy piszący wzory nie są istotnym z biznesowego punktu widzenia klientem firmy.
No cóż. Używajcie LaTeXa!
PS Gdyby poprawka bezpieczeństwa pozostawiłą na dysku plik fontu mtextra.ttf problemy byłyby ciut mniejsze.
PPS Tak, firma Microsoft wypuściłą odpowiednią poprawkę (instalujacą font) ale nie do wszystkich wersji swojego oprogramowania.
Na początku czerwca wziąłem udział w organizowanym przez Politechnikę Wrocławską, w ramach programu Innowacyjna Uczelnia — Innowacyjny Nauczyciel, kursie „LaTeX tworzenie profesjonalnej prezentacji”. Zajęcia prowadził Konrad Kluwak z Wydziału Elektroniki.
Szesnastogodzinny kurs oceniam pozytywnie — wydaje mi się, że może być rzeczywistą podstawą (dla zmotywowanego uczestnika) do rozpoczęcia przygody z LaTeXem.
Przy okazji kursu — za zgodą prowadzącego — opowiedziałem o beamerowym szablonie i o alternatywnej metodzie tworzenia prezentacji w języku Markdown konwertowanej do PDF z użyciem programu pandoc i LaTeXa/beamera. Opisywałem to już gdzie indziej i tam dostępne są slajdy.
Spotkanie było też okazją do usłyszenia paru uwag na temat szablonu i przedyskutowania możliwych udoskonaleń. Jeżeli chodzi o zgłoszone uwagi to:
Zbyt „agresywny” kolor spisu treści (Agendy).
Kwestia numerowania stron/slajdów.
Kolor spisu treści
Niestety jest jakiś poważny błąd w szablonie kolorów i przed zakończeniem sesji nie ma szans na przepisanie/przekonstruowanie go na nowo. Ale zmiany zostaną wprowadzone na początku wakacji.
Numerowanie stron/slajdów
Po pierwsze zauważyłem niesympatyczny błąd powodujący, że niektóre strony nie były numerowane.
Nie bardzo wiadomo co przyjąć za podstawę numerowania. Możliwości są, w zasadzie, tylko dwie:
numer strony z pliku PDF (było tak dotychczas),
numer slajdu (czyli numer kolejnego obiektu wstawianego środowiskiem frame).
W tym drugim przypadku, ze względu na to, że jeden slajd może być stworzony z kilku warstw, mamy do czynienia z sytuacją, że zawartość na ekranie się zmienia, ale nie zmienia się numer.
Parametrem sterującym wyświetlaniem numerów jest pagenumber. Może on przyjmować następujące wartości:
gdy opcja pagenumber nie występuje — nie będzie żadnej numeracji;
pagenumber=false — bez numeracji;
pagenumber=true — numerowane będą strony pliku PDF;
pagenumber=page — numerowane będą strony pliku PDF;
pagenumber=frame — numerowane będą slajdy;
pagenumber=slide — numerowane będą slajdy (ze względu na nieporozumienia językowe).
Standardowo slajd tytułowy nie jest numerowany.
Uaktualniona wersja szablonu, wraz ze zmienioną dokumentacją dostępna jest tam gdzie zwykle:
Bardzo często, po dodaniu ilustracji, plik PDF puchnie do ogromnych rozmiarów. Przygotowując publikację do druku staramy się aby jakość ilustracji była jak najlepsza i czasami przesadzamy z tym.
Osobną sprawą jest przygotowanie ilustracji w takiej rozdzielczości, aby drukarz (albo redakcja nie narzekali). Nie będziemy zajmować się tym teraz.
Program Adobe Acrobat (w wersji pro) pozwala zapisać plik w wersji „zoptymalizowanej”. Opis tej funkcjonalności można znaleźć na stronach Adobe.
Co jednak zrobić gdy nie mamy dostępu do tego (płatnego) programu?
Program ghostscript oferuje zbliżoną funkcjonalność.
Podstawowe polecenie do optymalizacji wygląda tak:
Kluczowa opcja to -dPDFSETTINGS=/printer która stara się działać podobnie jak odpowiednie ustawienie w Adobe Acrobat. Inne wartości jakie może ona przyjmować to:
/prepress — najwyższa jakość, 300 dpi,
/printer — wysoka jakość, optymalizowane do wydruku, 300 dpi,
/ebook — niska jakość, 150 dpi,
/screen — do czytania na ekranie, ilustracje są skalowane do 72 dpi (co nie zawsze daje dobre efekty)
/default — ustawienia domyślne.
Wykonany test pozwolił skompresować plik o wielkości 5 M do:
244 K /screen
276 K /ebook
632 K /prepress
704 K /print
788 K /default
W przypadku plików PDF tworzonych przez narzędzia TeXowe warto skorzystać z programu pdfimages znajdującego się w linuksowym pakiecie poppler-utils. W przypadku Windows (nie testowałem) program znajduje się w paczce pakietu XpdfReader. Program nie tylko pozwala na wyodrębnienie ilustracji zawartych w pliku PDF (nie każdą ilustrację i nie z każdego pliku da się w ten sposób wyodrębnić) ale, w szczególności, program pozwala odpytać o wszystkie ilustracje znajdujące się w pliku PDF:
Shell
1
pdfimages-list plik.pdf
Dowiemy się w jakiej rozdzielczości są ilustracje. Po kompresji okaże się co z nimi zrobił ghostscript.
W opisywanym wcześniej przykładzie było sporo plików graficznych w rozdzielczości 945 dpi. Po kompresji zostały one odpowiednio zmniejszone (do 300 dpi) w przypadku /printer.
Wadą tak zrealizowanej kompresji jest to, że wszystkie „klikalne odsyłacze” w pliku PDF przestają być klikalne. I nie tyle jest to wina LaTeXa/ghostscripta ile raczej sposobu traktowania różnych obiektów podczas kompresji. Aby odnośniki pozostały klikalne — należy (nad)użyć opcji pdfa pakietu hyperref:
Upłynęło już trzynaście lat od czasu opublikowania Księgi Logotypu Politechniki Wrocławskiej (SIW). W tym czasie zmieniło się bardzo wiele, a do najważniejszych (formalnych) zmian należy zaliczyć:
zmianę oficjalnej angielskiej nazwy Politechniki Wrocławskiej na Wrocław University of Science and Technology,
uzyskanie prawa do korzystania z logo HR Excellence in Research.
Spowodowało to konieczność dokonania odpowiednich zmian w SIW. Zmieniły się zwłaszcza szablony prezentacji. Nowa księga logotypu znajduje się, między innymi, tu.
Od początku roku, najpierw bardzo leniwie, później w nieco lepszym tempie zabrałem się za dokonywanie odpowiednich przeróbek. Pierwsza zapowiedź i proof of concept pojawił się 7 marca 2017 roku we wpisie Nowy logotyp Politechniki Wrocławskiej.
Już w semestrze letnim 2016/2017 znaczna część moich prezentacji (dydaktycznych) korzystała z pierwszych wersji szablonu. Ale dopiero podczas wakacji nabrał on ostatecznego kształtu. Później prace znowu zwolniły — trzeba było nie tylko testować zaproponowane rozwiązania, ale również tworzyć dokumentację.
Dziś pierwsza, nieśmiałą próba prezentacji szablonu szerszej publiczności.
Więcej informacji na jego temat można znaleźć w dziale Projekty.
System LaTeX posiada (może nie znakomite, ale całkiem niezłe) narzędzie do tworzenia bibliografii. Jest to system BibTeX.
Działa on w ten sposób, że tworzymy bazę danych zawierające wszelkie niezbędne informacje o publikacjach, a pisząc pracę odwołujemy się do rekordów tej bazy. Każdy rekord powinien posiadać swój unikatowy identyfikator służący do tworenia odwołań. Każdy rekord powinien zawierać minimalny, niezbędny zestaw informacji bibliograficznych. Zestaw ten jest różny dla różnych publikacji: inny dla artykułu, a inny dla książki. W najprostszym wypadku w tekście umieszczamy polecenie
\cite{identyfikator_rekordu} i o sprawie ,,zapominamy”.
Druga część systemu to mechanizm pozwalający podczas kompilacji dokumentu wyciągnąć z bazy danych informacje o cytowanych dokumentach i sformatować je zgdonie z wymaganym szablonem, a następnie wszystko połączyć w całość: w miejscu tekstu gdzie pojawiło się odwołanie do rekordu (
\cite{identyfikator_rekordu}) pojawi się odpowiedni symbol cytowania (na przykład liczba w nawiasach kwadratowych: [123]), a w innym miejscu (na przykład na końcu dokumentu) pojawi się ułożona w zdefiniowanej kolejności (alfabetycznie, według nazwisk pierwszego autora, albo chronologicznie według dat publikacji, albo w kolejnosci cytowania w pracy) lista prac (oznaczonych odpowiednimi symbolami). Numerkami w nawiasach kwadratowych, na przykład. Co więcej bibliografia będzie sformatowana zgdonie z wymaganiami wydawcy (co, swoją drogą jest sporym problemem: dobrzy wydawcy dostarczają odpowiednie szablony, kiepscy mają jedynie wskazówki jak powinien wyglądać wpis dotyczący książki, artykułu, referatu konferencyjnego,… Wówczas Autor musi albo taki szablon stworzyć (nie zawsze jest to łatwe) albo wybrać taki, który jak najbardziej jest zgodny z oczekiwaniami wydawcy. To też nie jest łatwe.
Osobną kwestią jest wypełnienie bazy danych rekordami. Tak się składa, że system BibTeX jest jednym z niewielu standardów udostępniania informacji bibliograficznych powszechnie uznanych i stosowanych przez naukowców na całym świecie (choć niekoniecznie w Polsce). W związku z tym bardzo wielu wydawców i większość publikacyjnych baz danych oferuje metadane artykułów w tym formacie. Istnieją również narzędzia pozwalające na podstawie DOI odzyskanie metadanych w formacie BibTeXa (http://www.doi2bib.org/).
Najlepszą metodą tworzenia takiej bazy jest metoda ręczna: jak mamy w ręku oryginał tekstu, który chcemy w niej zachować, wpisujemy do bazy niezbędny zestaw informacji. Program JabRef podpowie, które pola są niezbędne. Nie jest to wielka praca, ale trzeba ją wykonać wtedy kiedy oryginał mamy w ręku.
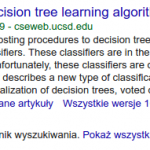
Z drugiej strony cytujemy często prace które znajdujemy w Internecie poszukując określonych słów kluczowych albo fraz. Google Scholar oferuje możliwość udostępnienia informacji blibliograficznych. Załóżmy że szukamy tekstu zatytułowanego The alternating decision tree learning algorithm. Google Scholar znajduje nawet tekst źródłowy, co więcej informuje, że artykuł jest całkiem popularny (jest tam informacja ile razy był cytowany).
Jest wreszcie informacja pozwalająca mająca, w zamierzeniu Autorów systemu, ułatwić zacytowanie artykułu. Klikamy w ,,Cytuj” i w następnym okienku znajdujemy możliwość uzyskania cytowania w formacie BibTeXa.
Bardzo wielu PT Twórców mając coś takiego wkleja odpowiedni rekord do swoje bazy danych. Wyszukiwarka jest wspaniała! Znalazła nam pożyteczny tekst, znalazła jego wersję elektroniczną i jeszcze oferuje metadane. A wszystko za darmo!
Problem pojawi się na znacznie późniejszym etapie, podczas formatowania bibliografii, gdyż jako tytuł książki w której ukazał się artykuł konferencyjny mamy podanie ,,icml”, a cytowana praca objawia się tak:
[50] Y. Freund and L. Mason, The alternating decision tree learning algorithm,” in icml, Vol. 99, 1999, pp. 124–133.
I takie kursywiane icml przyciąga uwagę i, właściwie, nie pozwala na odnalezienie oryginału w sposób klasyczny (to znaczy nie korzystając z Internetu). Można, oczywiście, machnąć na to ręką: jak ktoś nie ma Internetu niech zajmie się czym innym niż pisaniem prac. Sam tytuł pozwala dosyć łatwo pracę odnaleźć (i wielu PT Autorów wychodzi z tego założenia dostarczając czasami tylko tytuł, albo tytuł i nazwisko jednego z twórców). W tym przypadku zaprotestowała Redakcja Techniczna czasopisma: zadając pytanie ,,To gdzie ta praca została opublikowana?” Ale Google Scholar podaje tylko ten wynik. Bo najlepszy, bo z tekstem źródłowym.
Po przełączeniu się na wyszukiwarkę normalną dostajemy nieco więcej informacji. Znajdujemy odsyłacz do biblioteki elektronicznej ACM, gdzie jest już nieco więcej informacji na temat źródła, co więcej również tu możemy poprosić o rekord zawierający metadane referatu w formacie BibTeXa:
Wszystko, oczywiście w jedynie słusznym formacie.
Instrukcja tworzenia prezentacji pokazuje sześć, różnych, przykładowych slajdów tytułowych oraz osiem przykładów slajdów pozostałych (dla szablonu 1) oraz po siedem przykładów slajdów tytułowych i zwykłych dla szablonu drugiego. Ale na dobrą sprawę layouty są elastyczne, dając wiele możliwości układu tekstu, zdjęć i infografik jak mówi instrukcja. Na dobrą sprawę hulaj dusza piekła nie ma.
Niestety natłok bieżących obowiązków i zdarzające się sytuacje „nadzwyczajne” (w rodzaju awarii) utrudniają systematyczne rozpracowanie problemu i stworzenie szablonów.
Na szybko przykład w jaki sposób szybko przerobić prezentację na coś co będzie ± zgodne z oficjalnym szablonem.
Najpierw jednak parę uwag:
Wszystko jest oczywiście windowsowe, więc szablony korzystają z fontu Calibri.
Nieszczęśliwie dosyć jako tło wybrano dosyć fikuśny wzorek, który jest trochę inny w każdym punkcie slajdu — wygeneruje to ogromne ilości brzydkich slajdów (zawierających, na przykład, wykresy na białym tle).
Przykład takiego slajdu (choć nie najgorszy jeszcze) znajduje się w cytowanej instrukcji.
Szablony nie bardzo uwzględniają inne niż 4:3 proporcje ekranu (na przykład 16:9) gdyż tło ma rozmiar 1500×1125 pikseli.
Zamiast fontu Calibri użyjemy fontu Carlito dostępnego na CTAN. Choć skoro jest wolność ja wolę font Kurier albo Iwona.
Tła z prezentacji uzyskamy z rozpakowania (prezentacje pptx to w istocie pliki zip) szablonów prezentacji.
„Zabawę” rozpoczniemy od szablonu z poniższym tłem:
Prawdę mówiąc ten układ podoba mi się bardziej.
Aby dołączyć do każdego slajdu tło należy użyć poleceń:
(obrazek image2_p2_pl.png to ten z „wąskim paskiem” został on tak umieszczony na slajdzie aby dobrze było widać logo Politrechniki umieszczone w prawym górnym rogu).
Dla slajdu tytułowego używamy pliku z „szerokim paskiem”, a tło dla tego slajdu definiujemy w sposób następujący:
trzecim slajdzie umieściłęm obrazek, w którym kolor biały skonwerowałem na kanał alpha, co uczyniło go przezroczystym. W efekcie białę tło nie razi tak bardzo odcinając się od kratki z efektami gradientu. Również całkiem nieźle tło wpasowało się w „niestandardowy” format slajdu.
Jak wiadomo pisanie artykułów naukowych to bardzo ciężkie zadania. Wymaga wspomagania. Najpowszechniejszym wspomaganiem jest picie kawy. Na biurku pełno papierów, po łyku kawy odstawiamy filiżankę. A czasami (gdy się nie uda — możemy obejrzeć efekt w postaci różnych śladów na testowych wydrukach artykułu. A jak już kto ma wąsy, to wie, że lubią one moczyć się w napoju, a później resztki spadają na papier. Kropla kawy zaczyna rozpływać się na papierze, schnąć tworząc różne dziwne efekty.
Może to być podstawą badań naukowych, ale też rozważań bardziej rozrywkowych: jak pokazać światu, że nasz artykuł powstał w wyniku ciężkiej pracy wspomaganej piciem dużej ilości kawy?
Bardzo to proste — należy użyć dodatkowego pakietu dostarczanego przez zasoby tworzone przez miłośników i fanatyków LaTeXa.
Nie, nie całkiem. Ciągle jesteśmy Politechniką Wrocławską. Zmieniła się jedynie nasza angielska nazwa z Wrocław University of Technology na Wrocław Univeristy of Science and Technology.
Generuje to konieczność dokonania zmian w szablonie prezentacji, papieru firmowego, wizytówki czy modyfikacji wyglądu angielskojęzycznych stron WWW.
W związku z przygotowaniem samozwańczego szablonu pracy dyplomowej w LaTeXu dostaję różne pytania. Odpowiedzi na większosc z nich znaleźć można na stronie FAQ.
Przyznać muszę, że niemałą część pytań związana jest z przyzyczajeniem — tak studentów jak i promotorów — do korzystania z najpopularnijeszego procesora tekstu, mającego już dobrze ponad 30 lat, MS Worda. Produkt porządnie zakorzenił się na rynku, ma swoich zagorzałych zwolenników i stał się standardem de facto procesora tekstu. Używany jest do wszystkiego: wielu użytkowników jak ma przesłać obrazek tworzy prosty dokument, umieszcza w nim obrazek i wysyłą powstały w ten sposób plik DOC (a teraz tgo pewnie już docx).
Jak pamiętam, standardowo, dzielenie wyrazów jest wyłączone i (chyba?? tak piszę, bo programu nie używam już od bardzo wielu lat) włączone jest równanie do prawego marginesu. Stworzony w ten sposób tekst piękny nie jest, ale może być traktowany jako pewnego rodzaju wzorzec czy może standard właśnie. Najśmieszniejsze jest to, że już od bardzo dawna Word wyposażony jest nie tylko w słownik języka polskiego (z czego wszyscy chyba chętnie korzystają) ale i w zestaw wzorców przenoszeń dla języka polskiego. Łatwo więc uzyskać efek normalny, do którego przyzwyczajeni jesteśmy z książek drukowanych czy gazet. Który, coraz częściej, pojawia się na stronach WWW.
Tak więc zdziwiłęm się okrutnie, otrzymawszy list następujacej treści od jednej ze studentek: Panie Doktorze, Jak wyłączyć dzielenie wyrazów (odgórnie, wszystkich)? Moja promotor stwierdziła, że żaden wyraz nie powinien być dzielony i przenoszony, bo to wygląda nieprofesjonalnie.
Z poważaniem
I mnie zamurowało. Nie z powodu, że nie da się tego zrobić w LaTeXu. Z powodu użycia słówka nieprofesjonalnie. Gdyby użyto określenia „wygląda nieładnie”. OK Różne są gusta. Gdyby ktoś sugerował, że on jest przyzwyczajony do tekstów, w których wyrazy nie są przenoszone — również zdziwiłbym się, ale nie pyskował. Ale profesjonalizm? Czemu produkt gorszy (a który może być zrobiony lepiej) jest nieprofesjonalny? Może być nieekonomiczny, ale nie w tym przypadku — koszty potrzebne do realizacji podziału wyrazów na sylaby są minimalne.
No cóż, Klient nasz Pan. Pytanie trafiło do FAQ, i tam też znajduje się odpowiedź.
(Tekst w nagłówku za hasłem Dywiz z Wikipedii; po lewej bez przenoszenia, czyli profesjonalnie, po prawej nieprofesjonalnie.)